Overview of Last LLM in Medicine like never know before now
The revolution of Medicine raise with Lager Language model
Introduction
Larger language models have become a transformative force in the biomedical field, revolutionizing the way researchers and healthcare professionals approach complex challenges. These models, built on powerful transformer-based architectures, possess a remarkable ability to process and understand vast amounts of biomedical data, including text, images, and other modalities. Through pretraining on massive datasets and fine-tuning on specific biomedical tasks, these language models demonstrate exceptional performance in tasks like radiograph analysis, disease prediction, medical text generation, and cell type annotation. Their capacity to capture intricate relationships in biomedical data and facilitate knowledge transfer between domains has unlocked new possibilities for multimodal AI solutions, paving the way for groundbreaking advancements in healthcare and biomedical research.

In the rapidly evolving field of artificial intelligence (AI), transformer-based foundation models have emerged as a powerful tool for addressing various biomedical challenges. These models have been successfully applied in tasks such as radiograph analysis, biomedical text generation, disease prediction, and cell type annotation. The prevailing approach for developing biomedical foundation models is the pretraining-then-fine-tuning paradigm. Initially, a model is pre-trained on a large-scale dataset and then fine-tuned on specific downstream datasets, allowing knowledge transfer from one domain to another. Self-supervised approaches, which learn from vast amounts of unlabeled data without explicit human labeling, have gained popularity in contrast to supervised pretraining that relies on labeled data.
For biomedical natural language processing, models like BERT-derived and GPT-derived models have shown significant improvements in performance compared to earlier methods. In biomedical imaging analysis, the Vision Transformer (ViT) serves as a pretraining backbone for tasks like image segmentation, detection, classification, and synthesis, demonstrating promising results.
The increasing availability of biomedical data has paved the way for the development of multimodal AI solutions that integrate both vision and language information. Researchers focus on vision-language pretraining to enable multimodal models to understand images and textual contexts and accurately infer associations between them. They typically pre-train visual/textual embedders and cross-modal modules using image-text matching and masked language modeling objectives.
The CLIP architecture, which leverages contrastive pretraining to match paired image and caption embeddings while pushing others apart for better representation transferability, has also found applications in biomedical AI, achieving acceptable zero-shot performance.
However, existing labeled biomedical datasets are limited in volume and modalities, leading to a focus on either task/domain-specific or modality-specific applications. This limitation restricts the practical utility of these models. For instance, given the vast number of diagnosis codes in the International Classification of Diseases, tenth Revision (ICD-10), developing separate models for each disease is impractical and uneconomical. Moreover, such specialized models do not align with the comprehensive nature of healthcare, where seemingly unrelated diseases or symptoms often coexist and interact. Researchers have approached this issue through multitasking and transferring techniques, but these practices rely on strong assumptions like homogeneous structures or overlapping distributions in the available datasets.
1. Biomedical Multi-Modalities
we will cover some recent models in Biomedical that reach the Benchmark Performance on Task Q&A all of them based on Fine-Tune LLM model on Biomedical Data with additional techniques helps to make the model more scale and stable .
1.1 BiomedGPT
The BiomedGPT pipeline is a transformer-based architecture specifically designed for the biomedical field, building upon the success of existing unified models for general data. It adheres to three fundamental principles: Modality-Agnostic, Task-Agnostic, and Modality and Task Comprehensiveness. By discretizing data into patches or tokens, it achieves input/output unification, drawing inspiration from the Vision Transformer (ViT) and Language Models. The model is pre-trained on a diverse set of biomedical modalities and tasks to enhance its transferability.
The architecture selection process involves three mainstream options: encoder-only, decoder-only, and encoder-decoder models. The encoder-only models, like BERT, focus on learning representations of inputs but may struggle with aligning qualitatively different modalities and conducting complex zero-shot prediction or generation. The decoder-only models, such as GPTs, handle multi-tasking but require pre-existing representations and lack joint learning capabilities. For BiomedGPT, an encoder-decoder architecture is chosen for its ability to map various modalities into a unified representation space and handle diverse tasks effectively.
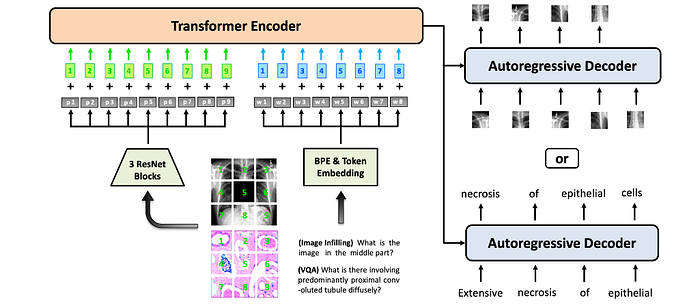
BiomedGPT is designed based on the BART backbone, with additional architectural changes to improve convergence efficiency and stability during pretraining. Absolute and relative position embeddings are incorporated for both text and images. The model can process inputs with various modalities, including images, language, and bounding boxes, by embedding them in a shared space. Visual inputs use CNN backbones for feature extraction, and linguistic inputs are tokenized using byte-pair encoding. The model represents diverse modalities with tokens drawn from a unified vocabulary, enabling it to handle multi-modal outputs without relying on task-specific structures.
Overall, BiomedGPT demonstrates a comprehensive and generalist nature, effectively handling a wide range of biomedical tasks while unifying different modalities within a single model.\
Natural Language serves as a versatile task manager for BiomedGPT, a unified and generalist model. Building on existing prompt/instruction learning approaches, and to eliminate task-specific modules, each task is specified with a handcrafted instruction. BiomedGPT supports various abstractions of tasks, encompassing vision-only, text-only, and vision-language tasks to achieve comprehensive task coverage.
In the pretraining phase, BiomedGPT is exposed to diverse tasks. For vision-only tasks, it performs masked image modeling and image infilling, where the model recovers masked patches in the middle part of images by generating corresponding codes. Additionally, it learns object detection by generating bounding boxes for objects in images. In the text-only task, the model engages in masked language modeling, predicting masked tokens in the text. For multi-modal tasks, it is trained on image captioning to describe images and Visual Question Answering to answer questions based on images and text.
During fine-tuning and inference, BiomedGPT is equipped to handle additional tasks beyond the ones used in pretraining. It includes one more vision-only task and two more text-only tasks. The vision-only task is not explicitly mentioned, while the text-only tasks use specific instructions to perform further text-related tasks.
Overall, Natural Language as a Task Manager enables BiomedGPT to efficiently handle a wide range of tasks by following the specified instructions, making it a powerful and adaptable model for various biomedical applications.
1.2 Med-PaLM 2
Just announced Med-PaLM M, the first-ever Generative Medical AI systemMed-PaLM 2 is an advanced artificial intelligence (AI) system developed to address the significant challenge of medical question answering, with the goal of approaching or surpassing human physician-level performance. This field of research has seen remarkable progress in AI systems, as demonstrated in various “grand challenges,” from playing complex games like Go to protein-folding. However, the ability to retrieve medical knowledge, reason over it, and provide accurate medical answers has remained a formidable task.
Large language models (LLMs) have been instrumental in advancing medical question answering. Med-PaLM was an early model that showed promising results by exceeding the passing score in the US Medical Licensing Examination (USMLE)-style questions, achieving a score of 67.2% on the MedQA dataset. Despite this success, there were still considerable opportunities for improvement, especially when comparing model answers to those provided by clinicians.
In response to these challenges, Med-PaLM 2 was developed, building upon the success of its predecessor and incorporating several key enhancements. One crucial aspect of the model is the improved base LLM, PaLM 2, which brings substantial performance improvements on various language modeling benchmarks. Additionally, Med-PaLM 2 underwent targeted domain-specific fine-tuning to optimize its performance for medical question answering tasks.
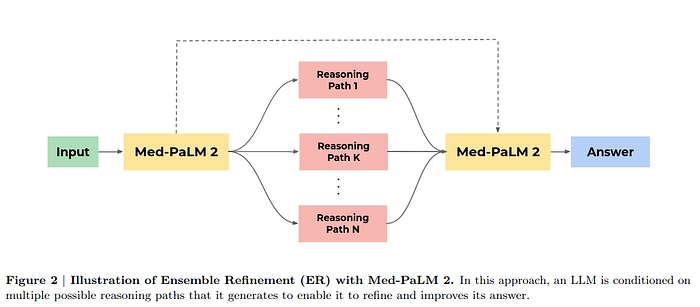
One of the novel features of Med-PaLM 2 is its innovative prompting strategy, which includes an ensemble refinement approach. This strategy leverages techniques like few-shot prompting, chain-of-thought, and self-consistency, further enhancing the model’s reasoning capabilities. By conditioning the model on its own generated explanations and answers, the ensemble refinement approach allows Med-PaLM 2 to consider multiple reasoning paths and produce more accurate responses.
The evaluation of Med-PaLM 2 involved multiple-choice and long-form medical question-answering datasets, including MedQA, MedMCQA, PubMedQA, MMLU clinical topics, and newly introduced adversarial long-form datasets. The model exhibited remarkable performance on these benchmarks, achieving state-of-the-art results and demonstrating its capacity to handle complex, real-world medical questions effectively.
To ensure the model’s safety and alignment with human values, extensive human evaluations were conducted. Physician and lay-person raters independently assessed model-generated answers, and Med-PaLM 2’s responses were consistently preferred over physician answers on various axes relevant to clinical utility. These axes included factuality, medical reasoning capability, and low likelihood of harm, among others.
Med-PaLM 2 represents a significant advancement in AI capabilities for medical question answering. Its ability to approach or exceed physician-level performance and its strong alignment with clinical utility make it a promising tool for medical professionals. While further validation in real-world settings is necessary, Med-PaLM 2’s rapid progress signifies a significant step towards achieving a deeper understanding of medical knowledge and enhancing human-AI collaboration in the medical domain.
Drug Discovery Medicine
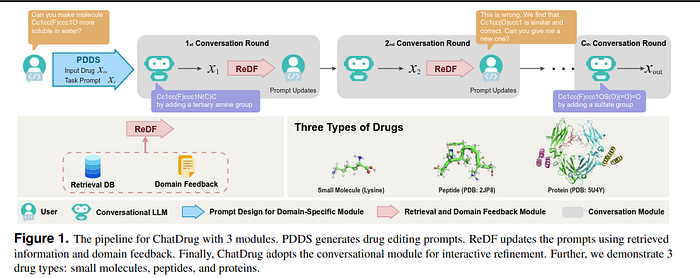
Recent advancements in conversational large language models (LLMs), like ChatGPT, have shown great potential in various domains, including drug discovery. However, existing research has mostly focused on investigating chemical reactions and retrosynthesis, neglecting drug editing, a crucial task in the drug discovery pipeline. To address this gap, we propose ChatDrug, a framework that leverages LLMs to facilitate systematic drug editing. ChatDrug combines a prompt module, a retrieval and domain feedback (ReDF) module, and a conversation module to streamline effective drug editing.
ChatDrug demonstrates promising results, outperforming seven baselines on 33 out of 39 drug editing tasks, involving small molecules, peptides, and proteins. Additionally, ChatDrug can identify key substructures for manipulation and generate diverse and valid suggestions for drug editing. It also offers insightful explanations from a domain-specific perspective, enhancing interpretability and enabling informed decision-making.
Conversational LLMs offer three compelling factors for drug discovery: pretraining on a vast knowledge base, fast adaptation and generalization through few-shot demonstrations, and interactive communication for dynamic exchange of information. These factors make them highly promising for drug editing tasks.
ChatDrug adopts a prompt design for domain-specific (PDDS) module, enabling strong prompt engineering from LLMs. It also integrates a retrieval and domain feedback (ReDF) module that guides prompt updates based on vast domain knowledge, leading to accurate outputs. The conversation-based approach aligns with the iterative refinement nature of the drug discovery pipeline, effectively incorporating domain expert feedback.
Empirical evidence demonstrates ChatDrug’s effectiveness for drug editing tasks, including an open vocabulary property allowing exploration of novel drug concepts and a compositional property that handles complex tasks by decomposing them into simpler attributes.
To verify ChatDrug’s performance, a benchmark with 39 drug editing tasks, involving small molecules, peptides, and proteins, is designed. Qualitative analysis through case studies further confirms the model’s ability to identify important substructures for different drug types.
Overall, ChatDrug showcases the untapped potential of conversational LLMs for drug editing tasks, offering insights into a more efficient and collaborative drug discovery pipeline, contributing to pharmaceutical research and development.
Conclusion
The combination of LLMs and biomedical research has paved the way for transformative advances in medicine and drug discovery. BiomedGPT and Med-PaLM 2 demonstrate the power of LLMs in handling diverse biomedical tasks, while ChatDrug showcases their potential for drug editing. These advancements hold tremendous promise in revolutionizing healthcare and driving pharmaceutical research and development to new heights. As the field continues to evolve, the potential of LLMs in biomedical applications is boundless, offering exciting opportunities for the future.
Reference
ChatGPT-powered Conversational Drug Editing
Using Retrieval and Domain Feedback
Towards Expert-Level Medical Question Answering
with Large Language Models
