Physics of Language Model || Transformer part 1
The Mechanism Mathematics Behind Attention all you need and improvement came after !!

recently whatever AI technology achieved now , in widely range of applications such text generation , image synthesis and others which can’t count how much products of AI out there . but specially Large Language models (LLM) are most impactful of the abilities of AI can , we made a touch with and we use everyday directly or indirectly in our days now . a lot big Techno companies such Meta FAIR and OpenAI , DeepMind took next step in their AI research Department to study in-depth LLM models to develop strategy to enhance the performance and try out to integrated LLM in robotics field like Google AI doing now by using PaLM to do multi-modalities interaction and multi-Task in case of learning Pathways ,
Notation: in this article we will focus on Language model understanding and Attention Mechanism At least to able to follow required simple knowledge about how Transformers works
What is a language model
The classic definition of a language model (LM) is a probability distribution over sequences of tokens. Suppose we have a vocabulary V of a set of tokens. A language model p assigns each sequence of tokens x1,…,xL∈V a probability (a number between 0 and 1) . p(x1,…,xL).
The probability intuitively tells us how “good” a sequence of tokens is. For example, if the vocabulary is V={ate,ball,cheese,mouse,the}, the language model might assign (demo):
p(the,mouse,ate,the,cheese)=0.02,
p(the,cheese,ate,the,mouse)=0.01,
p(mouse,the,the,cheese,ate)=0.0001.
Mathematically, a language model is a very simple and beautiful object. But the simplicity is deceiving: the ability to assign (meaningful) probabilities to all sequences requires extraordinary (but implicit) linguistic abilities and world knowledge.
please for more deep details follow reference Blow will Provide all info
in that simple definition of Language model we dive into one of most key concept called self-Attention which all the LLM built based on it and we will split into sub-sections
Transformers
is type of architecture Encoder-Decoder that map the data representation into different domain and also used for reconstruction Data . the first when Transformers came out is implement on Translation task , at this stage following Figure blow show the full Arch of Transformers in next we will dive for each individual components and explain later on , in general how does end-to-end Transformers work is A generic encoder/decoder architecture is composed of two models. The encoder takes the input and encodes it into a fixed-length vector. The decoder takes that vector and decodes it into the output sequence. The encoder and decoder are jointly trained to maximize the conditional log-likelihood of the output given the input. Once trained, the encoder/decoder can generate an output given an input sequence or can score a pair of input/output sequences.
In the case of the original Transformer architecture, both encoder and decoder had 6 identical layers. In each of those 6 layers the Encoder had two sub layers: a multi-head self attention layer, and a simple feed forward network. The self attention layer computes the output representation of each of its input tokens based on all the input tokens. Each sublayer also has a residual connection and a layer normalization. The output representation size of the Encoder was 512. The multi-head self-attention layer in the decoder is slightly different than that in the encoder. It masks all tokens to the right of the token whose representation is being computed so as to ensure that the decoder can only attend to tokens that come before the token it is trying to predict. This is shown in Figure blow “masked multi-head attention.” The Decoder also added a third sub-layer, which is another multi-head attention layer over all the outputs of the Encoder. Note that all those specific details have since been modified in the many Transformer variations we will discuss. For example, as we noted before, models like BERT and GPT are based on only the encoder or decoder.

now we will go to explain first side of Model Encoder because there’s no big different within Decoder just few modification to avoid cheating sequnces from decoder by apply masking to hide Token
Encoder
first of all , let us see how does input are feeds into the encoder to process , in NLP , we deal with words as vector representation , The encoder takes into input a sequence x = (x₁, x₂, …, xᵢ), compresses the first token x₁ , and each token relate to corresponding element of vector or matrix embedding in general we can defined Tokenization .
1. Tokenization
Tokenization is the process of dividing text into smaller units called tokens, which can be words, phrases, sub words, or characters. In the context of Transformer models, tokenization is a crucial step in preprocessing text data for use in natural language processing tasks, tokenization helps the model to identify the underlying structure of the text and process it more efficiently. It enables the model to handle variations in language and handle words with multiple meanings or forms. The choice of tokenization method depends on the task and language being processed and can be a major factor in determining the effectiveness of the model.
now we will see the first components in encoder blocks
Input embedding & Positional encoding
Transformers do not involve recurrence or convolution, so they do not know the order of the input tokens. Therefore, we need to explicitly tell the model where the token is. There are two sets of embedding for this. These are tokens (as we always have) and positions (new embedding needed for this model). Then the input representation of the token is the sum of its two embedding: the token and the position and is formulize in original paper following :

Unlike RNNs, which recurrently process tokens of a sequence one by one, self-attention ditches sequential operations in favor of parallel computation. Note, however, that self-attention by itself does not preserve the order of the sequence. What do we do if it really matters that the model knows in which order the input sequence arrived?
there’s more few techniques to do the embedding Positional such CLS-BERT ,

Self-Attention
we think about attention mechanism as block of Neural network which allow us to focus more on relevant features in text by giving high score probability attend to previous word or next one .

Self-Attention Mechanism (SAM) create to improve sequential modeling performance that solve recurrent and long memory which was most limitation comes over LTSM and RNN models and one of most archive by SAM is Parallel process of sequences we dived the this process by Query and Key and Value easier way to illustrate how does SAM works by taking for example Database search called look-up Table
- Query : is the SQL command that goes into Database system to find any similar content
- Key :play the role of whatever you looking for such for Key==”Deep learning Course”
- Value : we can say is target content we want to have
may ask yourself since that Query and Key and Value a have different means but the feed the same input of data ,here where’s SAM comes to play around and find similarity between Q and K , V now let us first defined SAM formula in depth
Explain mechanism of Attention the “Look at Each Other” in Encoder Part:
Given a sequence of input tokens 𝐱₁, …, 𝐱ₙ where any 𝐱ᵢ ∈ ℝᵈ. 1 ≤ i ≤ n, its self-attention outputs a sequence of the same length 𝐲₁, …, 𝐲 ₙ, where function mapping to learn is following

Step 1 : initialize learnable Weights
and we have the embedding input that applied on Positional encoding it has size the of batch_size , max_length , embedding_size
as we explained early the attention contains there major components which are Query and Key , value , they are learnable weights Matrices Linear

Step 2 : Dot-Product Similarity
We then compute the dot-product similarity between the Query (𝐐) and Key (𝐊)

This results in a square matrix of size 𝑛×𝑛
the reason behind doing the dot product is to calculate the similarity between to Vectors in Euclidean Space which means tell us how much two vector are close to each but the output from Dot product not Scale that’s why we need to average the out weights matrix between 1 and 0
after compute the similarity between the Q and K we will need to obtain final out from using Attention Function Score . The softmax function ensures that the weights for each Value are positive, and sum to 1.

The dot product between both vectors has zero mean and a variance of . To ensure that the variance of the dot product still remains one regardless of vector length, we use the scaled dot-product attention scoring function. That is, we rescale the dot-product by . We thus arrive at the first commonly used attention function that is used, e.g. in Transformers

Final Stage
We obtain the final output matrix by concatenating the Weighted Sum matrices computed for each embedding in the input sequence:

The Self-Attention mechanism can be summarized with the following formula:

Thie Figure blow shows a simulation of the Self-Attention mechanism at the Encoder stage of a Transformer model. Each of the input embedding (represented by the colored squares) attends to all the other embedding, and produces a weighted sum of the Value embedding (represented by the circles). This process is repeated for each of the Encoder layers,

code :
Explain mechanism of Mask-Self-Attention “Don’t Look Ahead” in Decoder Part:
Self-attention in decoders is slightly different than in encoders. The encoder receives all the tokens at once and the tokens can see all the tokens in the input sentence, but the decoder generates one token at a time. During creation, you don’t know which tokens you will create in the future.
To prevent the decoder from looking ahead, the model uses masked self-attention. Future tokens are masked. Look at the illustrations.
But how can the decoder look ahead?
This is not possible during Generation. You never know what comes next. However, training uses reference translations (which we know of). So in training, we feed the entire target sentence to the decoder. Without the mask, the token can “see the future” and this is not what we want.
This is done for computational efficiency. Transformer has no recurrence, so it can process all tokens at once. This is one of the reasons machine translation has become so popular. It is much faster to learn than the once-dominant recurrent models. For cyclic model one training step takes O(len(source) + len(target)) steps whereas for Transformer it is O(1) i.e constant.
mathematics of Mask-Self-Attention
here only different between previous Self-Attention is that Self-attention in decoders is slightly different than in encoders. The encoder receives all the tokens at once and the tokens can see all the tokens in the input sentence, but the decoder generates one token at a time. During creation, you don’t know which tokens you will create in the future.
To prevent the decoder from looking ahead, the model uses masked self-attention. Future tokens are masked.

We apply a softmax function to the Similarity matrix after adding the mask matrix:

Here,𝐌 is a mask matrix that prevents the decoder from “looking ahead” in the sequence during training. It has the same dimensions as the Similarity matrix and is typically a lower-triangular matrix. This modified Self-Attention mechanism formula can be summarized as follows:
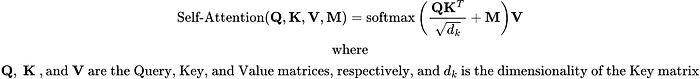
following the illustration blow show how does Masked avoid to prevent previous token be observe

Multi-Heads Self-Attention
In the Transformer, the Attention module repeats its computations multiple times in parallel. Each of these is called an Attention Head. The Attention module splits its Query, Key, and Value parameters N-ways and passes each split independently through a separate Head. All of these similar Attention calculations are then combined together to produce a final Attention score. This is called Multi-head attention and gives the Transformer greater power to encode multiple relationships and nuances for each word.

In general, to understand the role of a word in a sentence, you need to understand how it relates to other parts of the sentence. This is important not only when processing source statements, but also when generating targets. For example, in some languages, the subject defines the verb inflection (e.g. gender matching), the verb defines the case of the object, and so on. What I’m trying to say is that each word is part of many relationships. so we need to make the model focus on something else. This is the motivation behind Multi-Head Attention. Instead of using one attention mechanism, multi-head attention has multiple “heads” that work independently

This is implemented as several attention mechanisms whose outcomes are combined. The implementation simply splits the queries, keys, and values it computes into parts for single-head attention. In this way, models with one or more attention heads are the same size. Multi-head attention does not increase model size.
mathematics Proof


code
Transfomers
Now that you understand the main model components and the general idea, let’s take a look at the full model.Intuitively, the model is exactly what we discussed before. In the encoder, the tokens communicate with each other and update their representation. In the decoder, the target token first looks at the previously generated target token, then the source, and finally updates its representation. This happens in multiple layers, usually 6.
Let’s take a closer look at the other model components. :
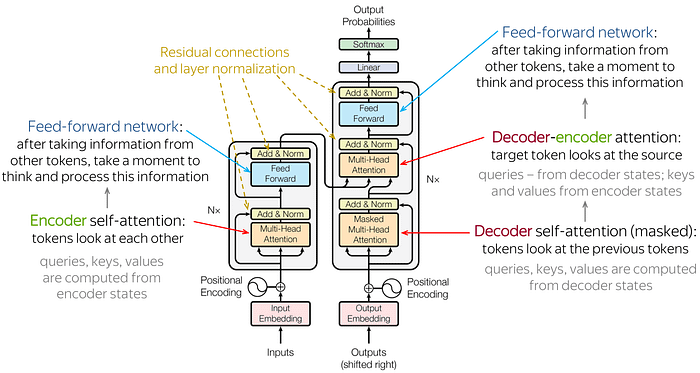
1. Residual connections
We already saw residual connections when talking about convolutional language models. Residual connections are very simple (add a block’s input to its output), but at the same time very useful. You can smooth out the gradient flow through the network and stack many layers. In Transformer, residual connections ((residual connections)) are used after each attention() and FFN block. In the picture above, the residuals are indicated by arrows coming around the block for the yellow “Add & Norm” layer. In the “Add & Norm” section, the “Add” section represents the residual connection

code :
2. Layer Normalization
The “Norm” part of the “Add & Norm” layer Layer Normalization represents . Normalize the vector representation of each example collectively and independently. This is done to control the “flow/flow” to the next layer. Layer normalization improves convergence stability and sometimes quality. In Transformer, we need to normalize the vector representation of each token. Also here LayerNorm is a learnable parameter that is used after normalization to rescale the layer’s output (or the next layer’s input). and There is. and is evaluated for each example, but and is the same. This is a layer parameter.

code
3. Positionwise Feed Forward
In addition to attention, each layer has a feedforward network block. There is a ReLU non linearity between the two linear layers. After looking at other tokens via the attention mechanism, the model processes this new information using the FFN block (attention — “gathers information by looking at other tokens”,FFN “Take time to think and process this information”)

code :
Summary
The Transformer is an instance of the encoder-decoder architecture, though either the encoder or the decoder can be used individually in practice. In the Transformer architecture, multi-head self-attention is used for representing the input sequence and the output sequence, though the decoder has to preserve the auto-regressive property via a masked version. Both the residual connections and the layer normalization in the Transformer are important for training a very deep model. The positionwise feed-forward network in the Transformer model transforms the representation at all the sequence positions using the same MLP.
References:
- Attention is All You Need paper : https://arxiv.org/abs/1706.03762
- Transformers in-depth and illustration by wikidocs: This resource provides a comprehensive explanation and visualizations of Transformers. It can help readers gain a deeper understanding of the model.: https://wikidocs.net/178418
- Transformers chapter from the book “Dive into Deep Learning” (DL2): This chapter covers the mathematical concepts and implementation details of Transformers. It is a valuable resource for understanding the theory behind Transformers.: https://d2l.ai/chapter_attention-mechanisms-and-transformers/transformer.html
- Transformers Explained: Mathematics and Code in-depth Kaggle notebook : This notebook provides an implementation of Transformers from scratch using numpy and PyTorch. It can be helpful for readers who want to see a practical implementation of the model.: https://www.kaggle.com/code/younesselbrag/transfomers-explained-mathematic-and-code-in-depth/notebook?scriptVersionId=129192633
- The repository contains a full implementation of Transformers using numpy. It can be a valuable resource for those interested in exploring a numpy-based implementation.: https://github.com/deep-matter/TransformersNumpy-Version
